Milestone Report
Robust Word Recognition
Zhao Cheng, Benjamin Walker
Summary
Our project is a robust word
recognition system specifically for low quality or poorly written images. This report discusses
the results and methods of character recognition to achieve the project
milestone objectives.
Results Overview
Successful implementation of 3
classifiers: Artificial Neural Network
(ANN), Decision Tree, and k Nearest Neighbor (kNN). The following table contains the
classification error rate for each method.
|
Algorithm |
Error
Rate(%) |
|
D-Tree |
19.8 |
|
kNN |
10.3 |
|
ANN* |
57.4 |
* Note that in this method, The ANN
has only one output
node, a different structure will be
implemented later.
Methodology
Character recognition was achieved
through the completion offour tasks. These tasks are image preprocessing, word
segmentation, feature extraction/classifier training, and classifier design.
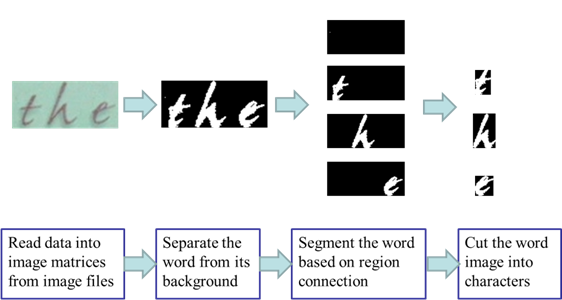
The objective of image processing is
to read the image data files and output the segmented character images. Four
steps is needed in this process, the first step is to read data into image
matrices from image file folder. Then, an unsurprised clustering algorithm is
used toseparate the word from its background. The word image is then
transformed from a color image into a black-white image. In order to segment
the words into individual characters, a region connection algorithm is
implemented. At last, the word is cut into several characters image. Some other
methods such as checking area of connected region are also applied to make this
process more robust to the noise. Here is an example,
(2)
Feature Extraction
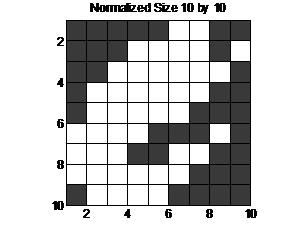
There are many methods available to
extract the feature of a character image. Among all these existing methods,
taking pixels directly out is perhaps the simplest and most straight forward
one. However, it is not possible to take pixels directly as size of character
images varies for different samples. In order to address this problem, we will
take the pixels from a resized image, say 10 by 10. Note that the normalized
size is not necessary to be set as 10 by 10, the Matlab function “GenerateDataset”
is designed to deal with any output size. From the figure, it is easily to show
that by downsizing the image, some of the critical information is lost.
However, if the size cannot be too large as the amount of sample data grows
squarely to the size.

(3)
Classifier Design
Three classification algorithms have
been implemented with varying degrees of success. The multiple classification techniques, including decision
tree, k-nearest neighbor (KNN), and Artificial Neural network (ANN). Finally, a
cross validation technique will be applied on the training dataset to assess the error rate.
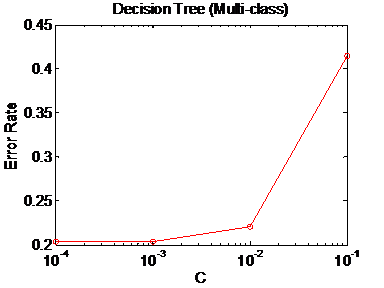
Decision Tree
Decision Tree is based on the binary
classification code of homework #2. However, this code does not work properly
unless we modify it so that it is capable to make predictions for multiple
classes. The modification includes two functions, the function “impurity.m” in
which we calculate the impurity and the function “declare leaves” in which
multi-class comparison is considered. We
have also tested the performance with 5-folder cross validation method on the
training dataset. In order to acess the parameters for this method, we have
designed the following possible values for parameter ![]() .
.
k-Nearest
Neighbor (kNN)
The kNN algorithm has a clear lead with
the lowest error rate. The
implementation of this one was fairly straight forward as it is able to handle
comparing many features. Handling the
voting process with an increasing k will require deft programming, but should
bring an even lower error rate.
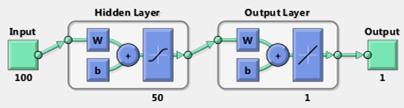
Artificial Neural Network (ANN)
Artificial
neural network is also implemented. The neural network we developed has 100
input nodes as each sample data has 100 attributes. A hidden layer is assigned
with 50 nodes. Only one node is assigned as the output. This design will
enforce all 26 difference classes share one output node. In order to
distinguished between multiple classes, the output nodes uses index number 1 to
26. This may induce close relation between these neighboring numbers, when in
fact the relation does not exist. The error rate could be as high as around 0.6
due to this fact. We should assign multiple output nodes to the ANN structure,
however, we had difficulty in handling the large amount of data.
Timeline
The project has
been partitioned into five tasks, each of which is evaluated and assigned,
|
Tasks |
Content |
Workload
(week) |
Completed ? |
|
Image Preprocessing |
Read data into image matrices from
image files Sharpen the image when necessary Separate the word from its
background by checking color histogram |
0.5 |
Yes |
|
Word Segmentation |
Segment the words based on region
connectionCut the image into characters |
0.5 |
Yes |
|
Feature Extraction & Classifier Training |
Apply a feature extraction
technique to train a classifierLearn algorithms with the following classifiers |
1.5 |
Yes |
|
Classifier Design |
Decision Tree k-nearest Neighbor (KNN) Support Vector Machine
(SVM)Artificial Neural Network (ANN) |
2 (0.5x4) |
Yes Work In
Progress |
|
Performance Assessment |
k-fold cross validation |
0.5 |
Work In
Progress |
|
Documentation & Presentation |
Milestone report, Final
reportPresentation |
1 |
Work In
Progress |
Future Work
Figure 1 shows the ambiguity in the
letter recognition problem. If we look from the top-down direction of the five characters
on the left, a sequence of letters (A, B, C) will come into one’s mind.
However, it will be a set of numbers (12, 13, 14) if we look from left to the
right. Recognition is a very hard problem, and trying to do it without
considering the context might result in a classification error. To figure this
out, we might need a dictionary or to build a dictionary by some kind of
learning techniques. Once we have the context, the classification rate might
improve dramatically. By checking the bottom right word in Figure 1, a
classifier would get the result “CQDE”, however this makes no sense for
human beings. The most possible reason is the written error of the letter “O”.
An auto-correction may be made with the context to help the machine understanding
(recognizing) words instead of isolated characters.
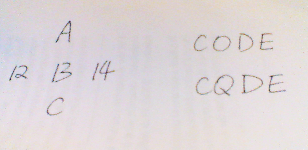
References
[1] Jonathan Connell and Vijay
Kothari, “Handwritten Character Recognition”, CS 74/174 - Spring 2012, final
report of term project
[2] Yuxi Zhang, “Optical Word
Recognition”, CS 74/174 - Spring 2012, final report of term project
http://www.cs.dartmouth.edu/~lorenzo/teaching/cs174/Archive/Spring2012/Projects/Final/yuxi_zhang/final_yuxi.html
[3]Shahab,
Asif; Shafait, Faisal; Dengel, Andreas; , "ICDAR 2011 Robust Reading
Competition Challenge 2: Reading Text in Scene Images," International
Conference on Document Analysis and Recognition (ICDAR), 2011 , pp.1491-1496,
18-21 Sept. 2011
[4]
ICDAR 2003 Competitions website, http://algoval.essex.ac.uk/icdar/
[5]
ICDAR 2005 Competitions website, http://algoval.essex.ac.uk:8080/icdar2005/
[6] ICDAR 2011 Competitions website, http://www.cvc.uab.es/icdar2011competition/
[7] http://archive.ics.uci.edu/ml/datasets/Letter+Recognition,
visited on 11/4/2011.